**发布时间:** 2025-03-20
**厂商:** GCP
**类型:** BLOG
**原始链接:** https://cloud.google.com/blog/products/networking/rdma-rocev2-for-ai-workloads-on-google-cloud
---
<!-- AI_TASK_START: AI标题翻译 -->
[解决方案] 在 Google Cloud 上为人工智能工作负载应用融合以太网 RDMA 网络
<!-- AI_TASK_END: AI标题翻译 -->
<!-- AI_TASK_START: AI竞争分析 -->
# 解决方案分析
## 解决方案概述
Google Cloud 推出基于 **RoCE v2 (RDMA over Converged Ethernet v2)** 协议的高性能网络解决方案,专为 **AI/ML** 和科学计算等高强度工作负载设计。该方案旨在解决传统网络通信中因 **CPU 和操作系统内核** 介入而导致的性能瓶颈。AI 工作负载对高带宽、低延迟和无损通信有极致要求,此方案通过 **RDMA (远程直接内存访问)** 技术实现 **内核旁路 (Kernel Bypass)**,允许网络接口卡 (NIC) 直接在不同节点的 GPU 显存之间传输数据,无需 CPU 或操作系统的干预,从而极大降低通信延迟,提升数据传输效率。RoCE v2 是在标准以太网上传输 RDMA 流量的行业标准协议,标志着 Google Cloud 在高性能网络领域向开放标准迈进。
## 方案客户价值
- **显著降低延迟:** 通过内核旁路技术,绕过操作系统和CPU,实现节点间 GPU 的直接内存访问,大幅缩短数据传输时间。
- **带宽翻倍:** 节点间 GPU 到 GPU 的通信带宽从 1.6 Tbps 提升至 **3.2 Tbps**,有效加速大规模分布式训练中的梯度同步和数据交换。
- **实现无损网络:** 借助 **PFC (Priority-based Flow Control)** 和 **ECN (Explicit Congestion Notification)** 等拥塞管理机制,确保在高速数据传输中不发生数据包丢失,保障 AI 训练任务的稳定性和效率。
- **提升应用性能:** _直接加速 AI 模型的训练和推理速度_,帮助客户更快地完成计算任务,优化资源利用率并降低总拥有成本。
- **增强可扩展性:** 专为大规模集群部署设计,采用优化的 **"rail-designed"** 网络拓扑,支持构建拥有数千甚至数万个加速器的超大规模 AI Hypercomputer。
## 实施步骤
1. **创建预留 (Create a reservation):** 首先需要为高性能计算实例申请并获取容量预留,并获得一个预留ID。此步骤可能需要与 Google Cloud 支持团队协调。
2. **选择部署策略 (Choose a deployment strategy):** 根据需求指定部署的区域、可用区、网络配置文件、预留ID以及部署方法。
3. **创建部署 (Create your deployment):** 使用 Hypercompute Cluster 等工具,根据所选策略执行部署操作,构建支持 RoCE v2 的高性能计算集群。
## 涉及的相关产品
- **Compute Engine 虚拟机:**
- **A3 Ultra:** 基于 NVIDIA H100 GPU 的 AI 优化实例。
- **A4:** 基于 NVIDIA B200 (Blackwell) GPU 的新一代 AI 优化实例。
- **网络:**
- **专用 VPC 网络:** 为 RoCE v2 流量优化的专用网络环境,使用 UDP 端口 `4791`。
- **NVLink:** 用于单个节点内部 GPU 之间的高速互联技术。
- **部署与管理:**
- **Hypercompute Cluster:** 用于创建和管理大规模 AI 计算集群的工具集。
## 技术评估
- **技术先进性:**
- **拥抱行业标准:** 从自研的 `GPUDirect-TCPX/TCPXO` 扩展到支持 **RoCE v2**,表明 Google Cloud 正在积极拥抱开放的行业标准。这增强了与第三方硬件和软件生态的兼容性,降低了客户的迁移和学习成本。
- **专为 AI 优化的网络架构:** 每个节点配备 8 个支持 RDMA 的 NIC,并采用 **"rail-designed"** 网络拓扑,确保了大规模集群中任意节点间通信性能的一致性和可预测性,这是大规模分布式训练成功的关键。
- **优势:**
- **性能卓越:** 3.2 Tbps 的节点间带宽和 RDMA 带来的超低延迟,为业界顶级水平,能够充分发挥最新一代 GPU 加速器的计算潜力。
- **端到端整合:** 将高性能计算实例 (A3/A4)、高速网络 (RoCE v2) 和集群管理工具 (Hypercompute Cluster) 深度整合,为客户提供了一站式的 AI 基础设施解决方案。
- **可能的限制:**
- **部署复杂性:** 启用此类高级功能通常需要预留容量并进行专门的集群规划与部署,对用户的技术能力有一定要求。
- **适用场景:** 该方案主要针对大规模、对网络极度敏感的 AI 训练和 HPC 场景,对于通用计算或小型 AI 任务可能成本过高。
<!-- AI_TASK_END: AI竞争分析 -->
<!-- AI_TASK_START: AI全文翻译 -->
# 在 Google Cloud 上为 AI 应用使用融合以太网上的 RDMA 网络
**原始链接:** [https://cloud.google.com/blog/products/networking/rdma-rocev2-for-ai-workloads-on-google-cloud](https://cloud.google.com/blog/products/networking/rdma-rocev2-for-ai-workloads-on-google-cloud)
**发布时间:** 2025-03-20
**厂商:** GCP
**类型:** BLOG
---
网络
#
在 Google Cloud 上为 AI 应用使用融合以太网上的 RDMA 网络
2025 年 3 月 20 日
##### Ammett Williams
Developer Relations Engineer
##### Google Cloud Next
即时访问 Next 大会的精华内容。
[立即观看](https://cloud.withgoogle.com/next/25?utm_source=cgc-blog&utm_medium=blog&utm_campaign=FY25-Q2-global-EXP106-physicalevent-er-next25-mc&utm_content=cgc-blog-left-hand-rail-post-next&utm_term=-)
并非所有工作负载都完全相同,对于人工智能 (AI)、机器学习 (ML) 和科学计算类工作负载而言尤其如此。在本篇博客中,我们将展示 Google Cloud 如何为高性能工作负载提供 [融合以太网上的远程直接内存访问第二版 (RDMA over converged ethernet version 2, RoCE v2)](https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet) 协议。
### **传统工作负载**
传统工作负载的网络通信遵循一个众所周知的流程,包括:
- 数据在源和目标之间移动。应用程序发起请求。
- 操作系统 (OS) 处理数据,添加 TCP 报头,并将其传递给网络接口卡 (NIC)。
- NIC 根据网络和路由信息将数据发送到网络中。
- 接收端的 NIC 接收数据。
- 接收端的 OS 处理过程会剥离报头,并根据信息交付数据。
这个过程涉及 CPU 和 [OS 处理](https://en.wikipedia.org/wiki/Process_management_(computing)) ,这类网络能够在出现延迟和丢包问题时进行恢复,并能正常处理不同大小的数据。
### **AI 工作负载**
AI 工作负载非常敏感,涉及海量数据集,可能需要高带宽、低延迟和无损通信来进行训练和推理。由于运行这类任务的成本更高,因此必须尽快完成并优化处理过程。这可以通过加速器——一种旨在显著加速 AI 应用训练和执行的专用硬件——来实现。加速器的例子包括 ****[TPUs](https://cloud.google.com/tpu/docs/intro-to-tpu#how_a_tpu_works) 和 [GPUs](https://cloud.google.com/tpu/docs/intro-to-tpu#how_a_gpu_works) 等专用硬件芯片。
### **RDMA**
[远程直接内存访问 (Remote Direct Memory Access, RDMA)](https://www.rfc-editor.org/rfc/rfc5040.html#section-1.1) 技术允许系统之间直接交换数据,无需操作系统、网络堆栈和 CPU 的参与。由于绕过了可能成为瓶颈的 CPU,这使得处理时间得以加快。
我们来看看它如何与 GPUs 协同工作。
- 一个支持 RDMA 的应用程序发起 RDMA 操作。
- 发生内核旁路 (Kernel bypass),绕过 OS 和 CPU。
- 支持 RDMA 的网络硬件介入,访问源 GPU 内存,并将数据传输到目标 GPU 内存。
- 在接收端,应用程序可以从 GPU 内存中检索信息,并向发送方发送确认通知。
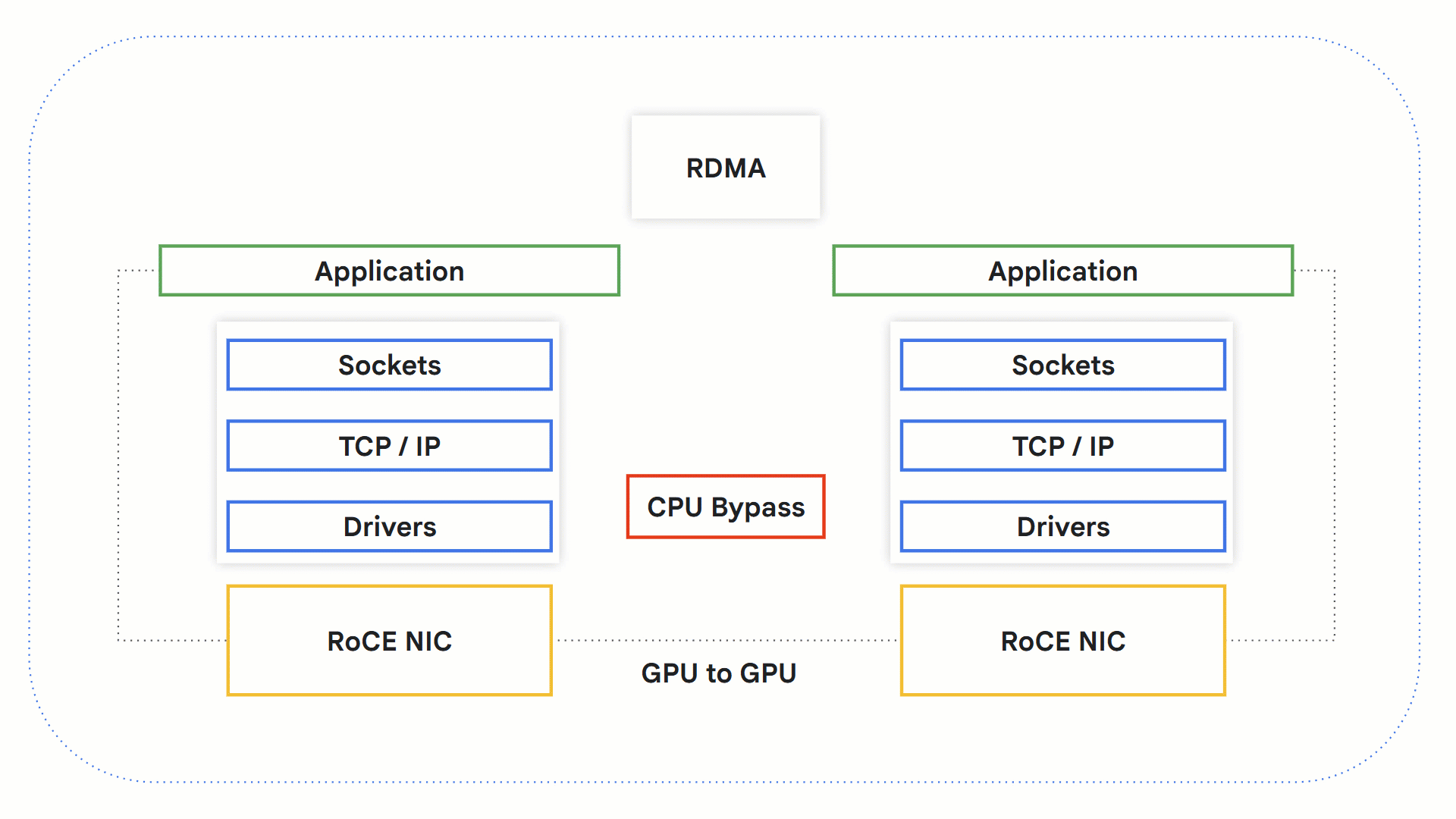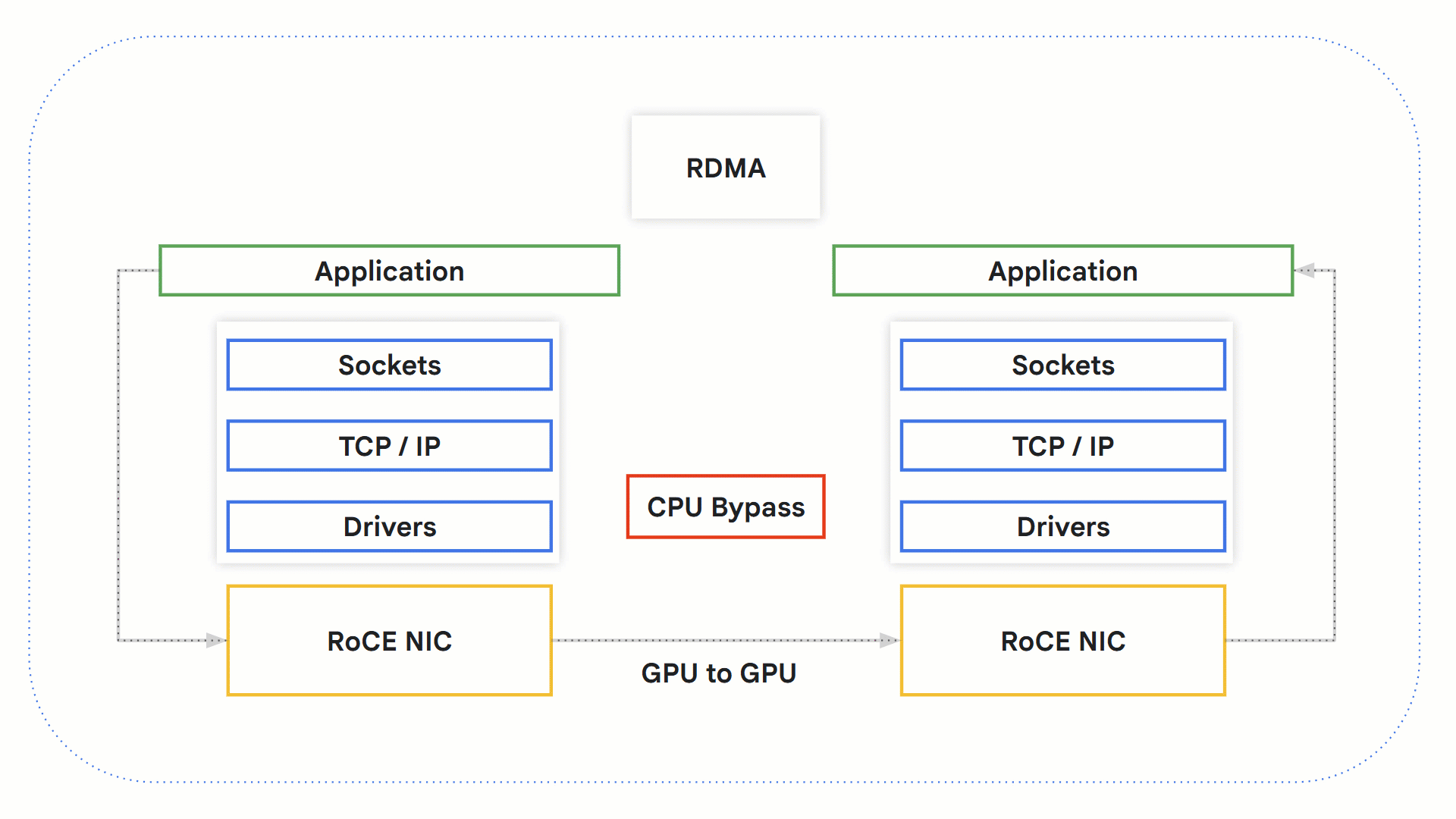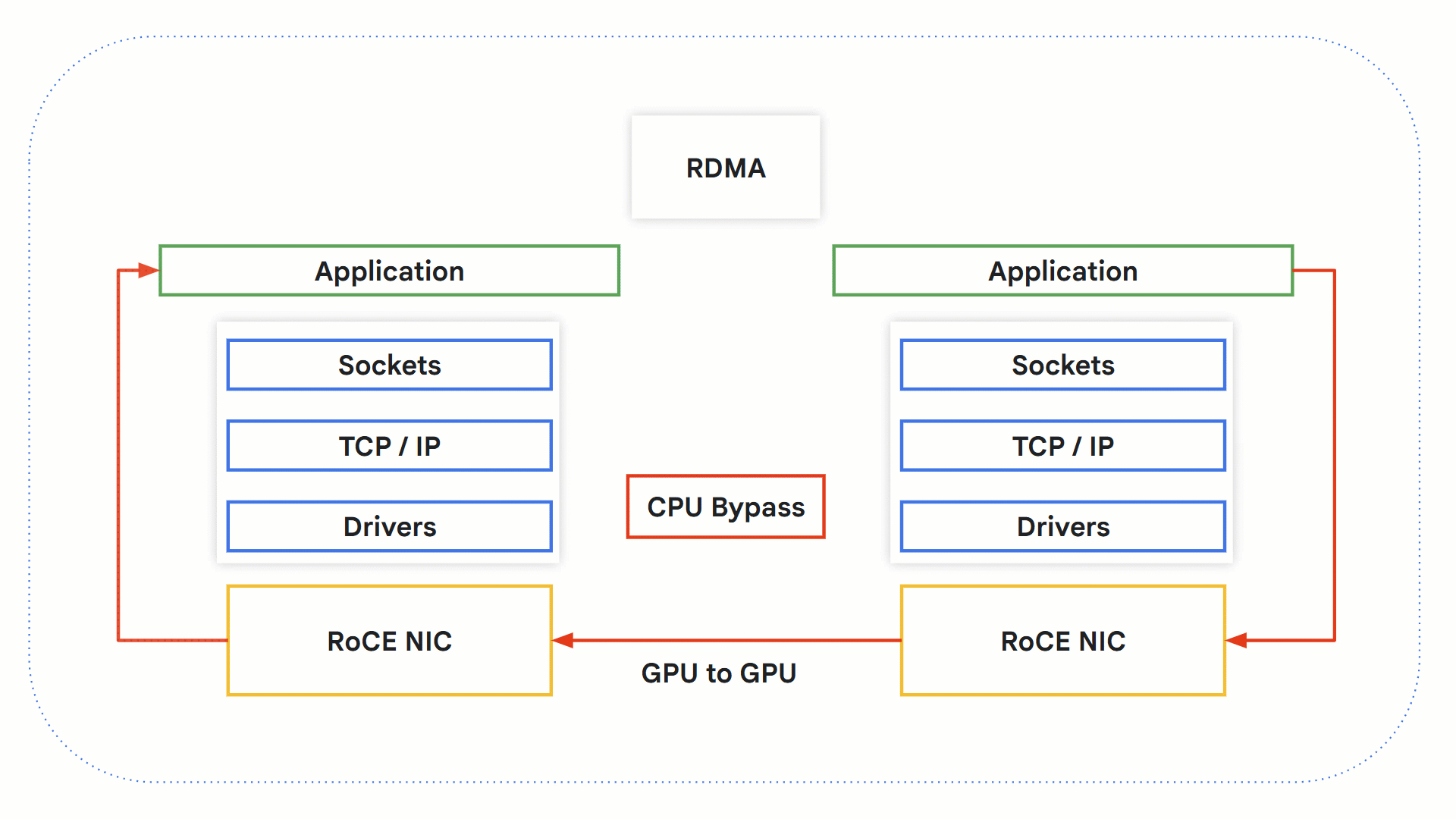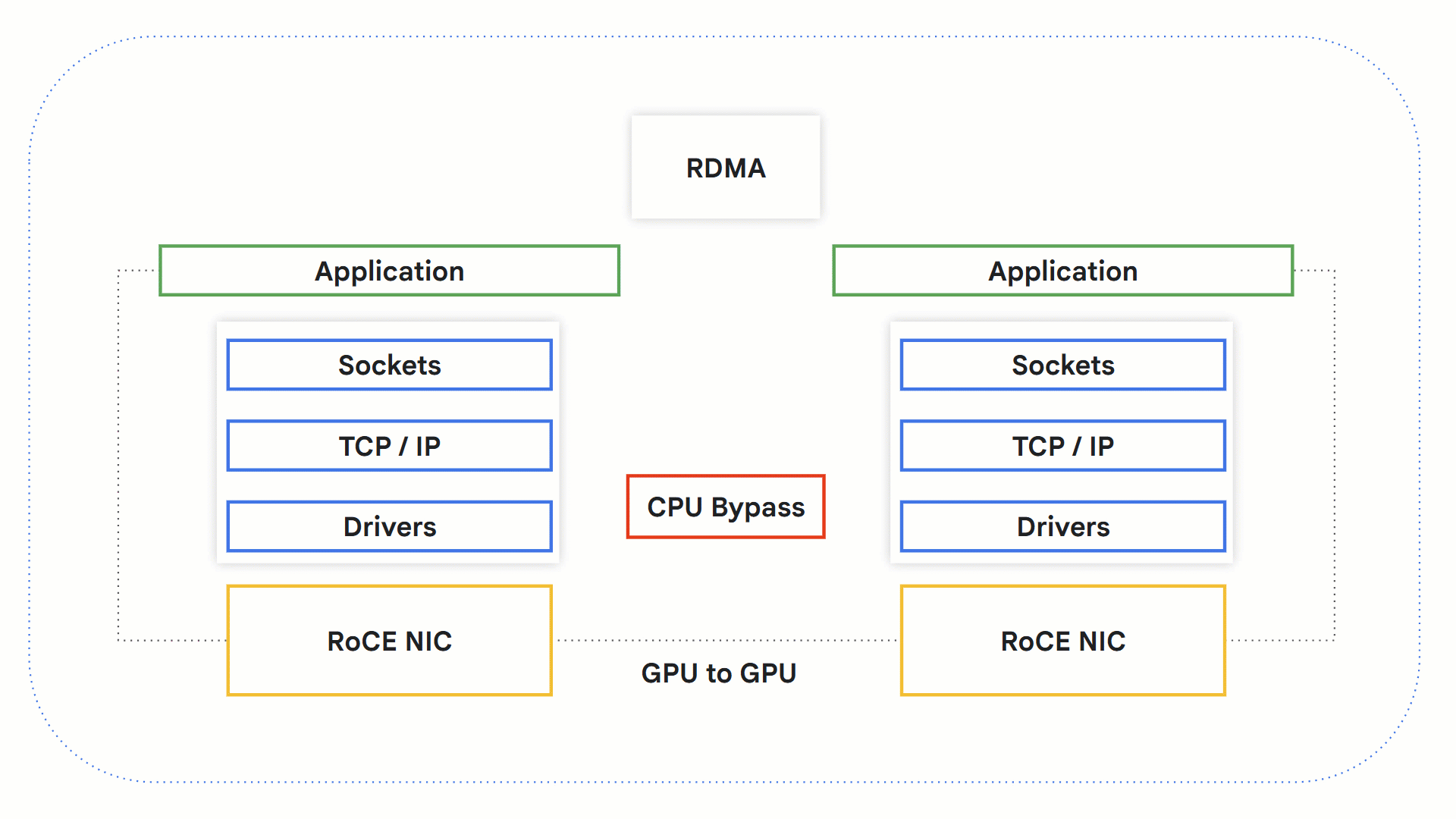
RDMA 与 RoCE 的工作原理
此前,Google Cloud 通过其自有的原生网络堆栈 [GPUDirect-TCPX](https://cloud.google.com/compute/docs/gpus/gpudirect) 和 [GPUDirect-TCPXO](https://cloud.google.com/cluster-toolkit/docs/machine-learning/a3-mega-enable-gpudirect-tcpxo) 支持类似 RDMA 的功能。目前,该功能已通过 RoCEv2 得到扩展,RoCEv2 实现了在以太网上传输 RDMA。
### **支持 RoCE-v2 的计算资源**
[A3 Ultra](https://cloud.google.com/ai-hypercomputer/docs/gpu#a3_ultra) 和 [A4](https://cloud.google.com/blog/products/compute/introducing-a4-vms-powered-by-nvidia-b200-gpu-aka-blackwell) 两种 Compute Engine 机器类型都利用 RoCE v2 实现高性能网络。每个节点支持八个支持 RDMA 的 NIC,连接到隔离的 RDMA 网络。节点内的 GPU 间直接通信通过 NVLink 进行,而节点间的通信则通过 RoCE 实现。
采用 RoCEv2 网络能力带来了更多好处,包括:
- 更低的延迟
- 更高的带宽——节点间 GPU 到 GPU 的流量从 1.6 Tbps 提升至 3.2 Tbps
- 通过拥塞管理能力实现无损通信:[基于优先级的流量控制 (Priority-based Flow Control, PFC)](https://1.ieee802.org/dcb/802-1qbb/) 和 [显式拥塞通知 (Explicit Congestion Notification, ECN)](https://datatracker.ietf.org/doc/html/rfc3168)
- 使用 UDP 端口 4791
- 支持 A3 Ultras、A4 及更高版本的新虚拟机系列
- 为大规模集群部署提供可扩展性支持
- 优化的轨道式设计网络
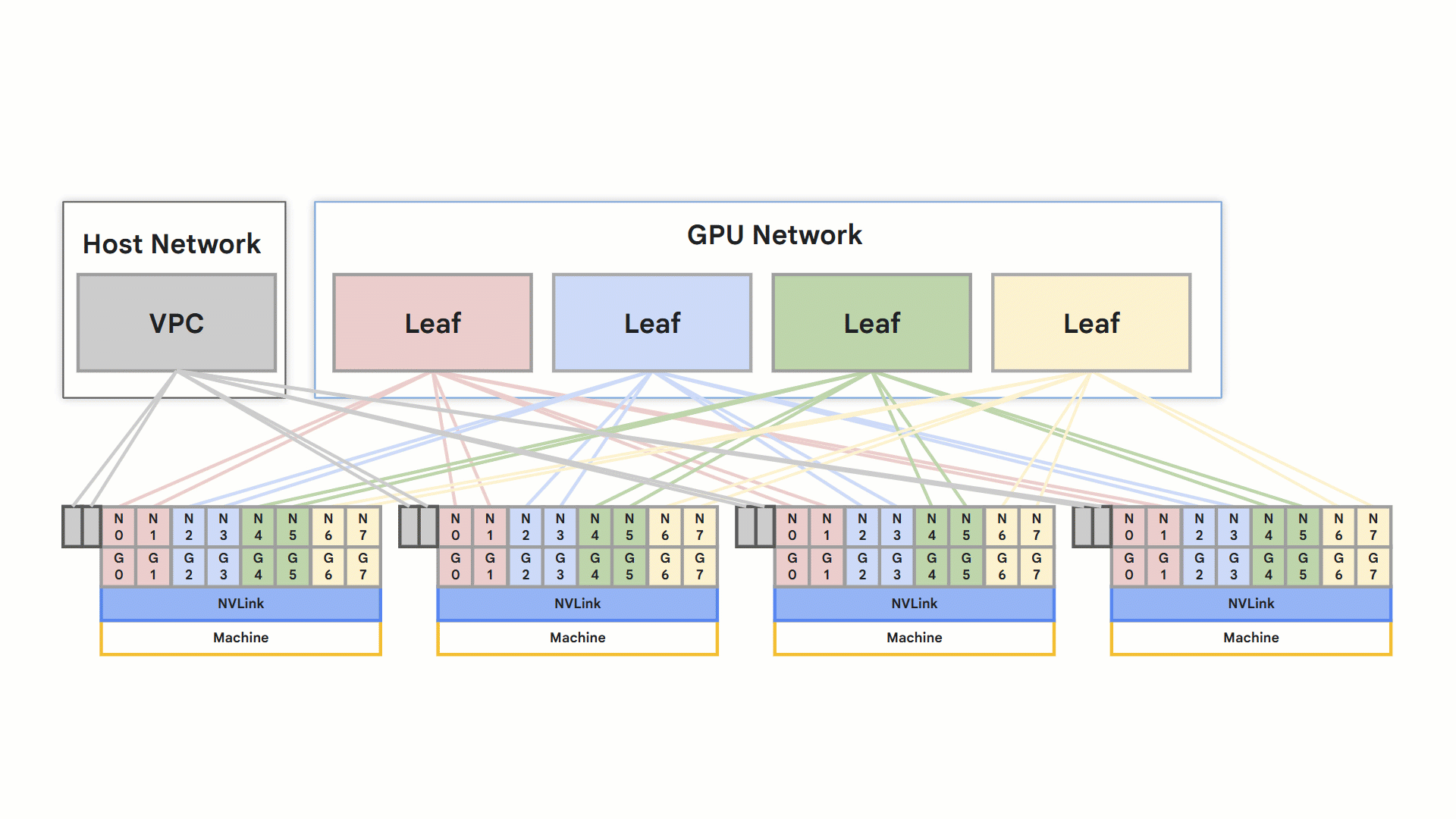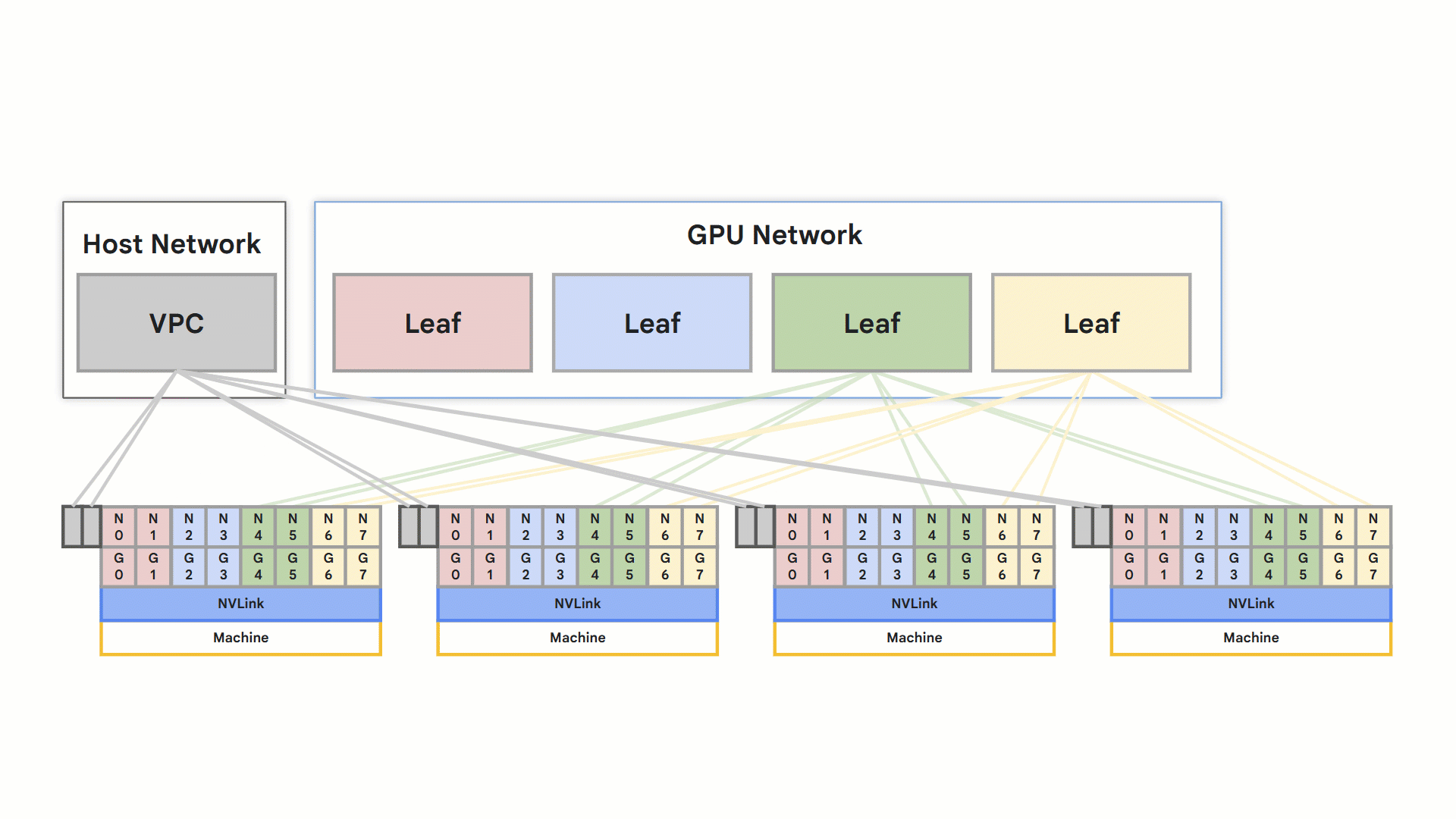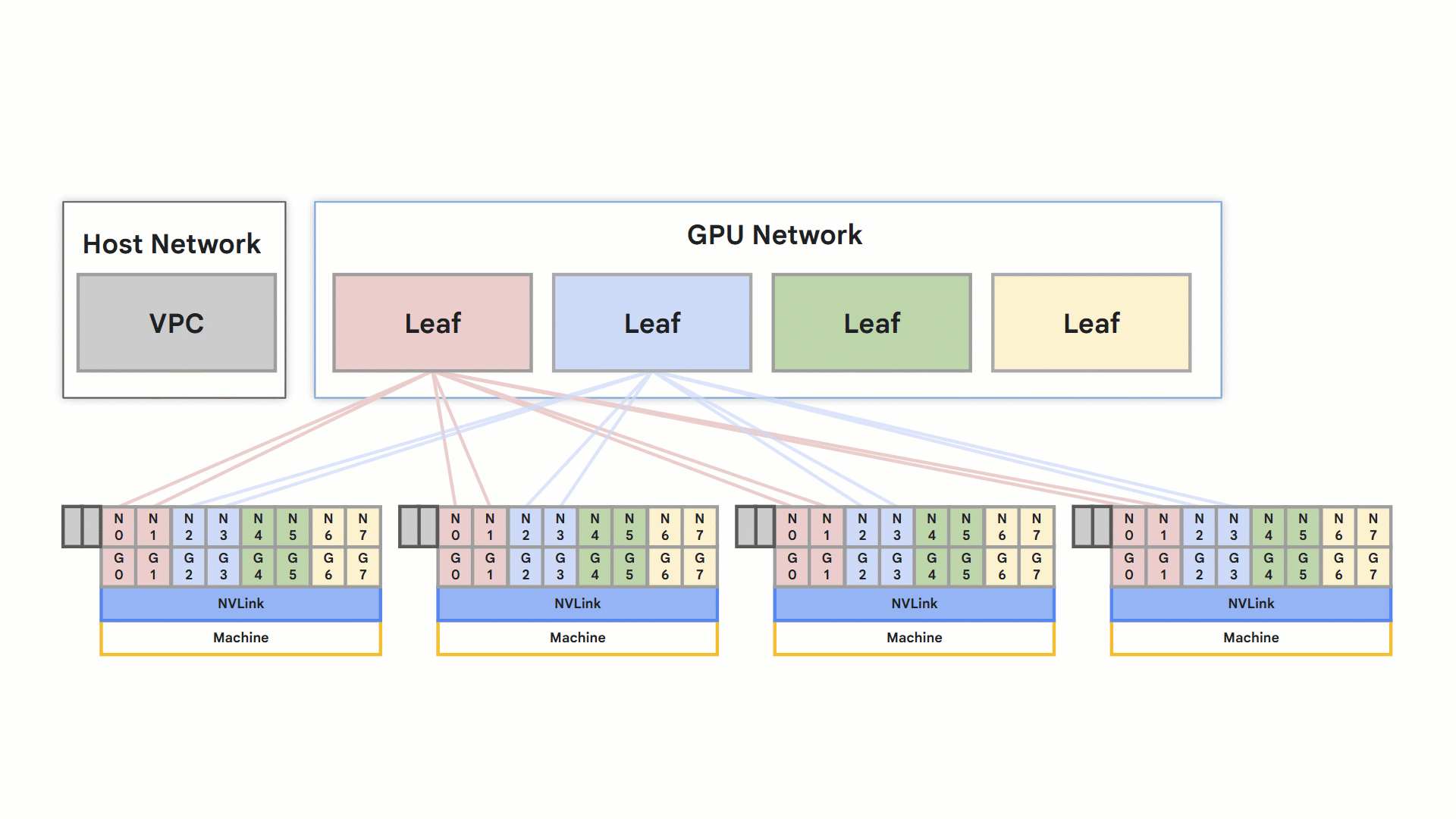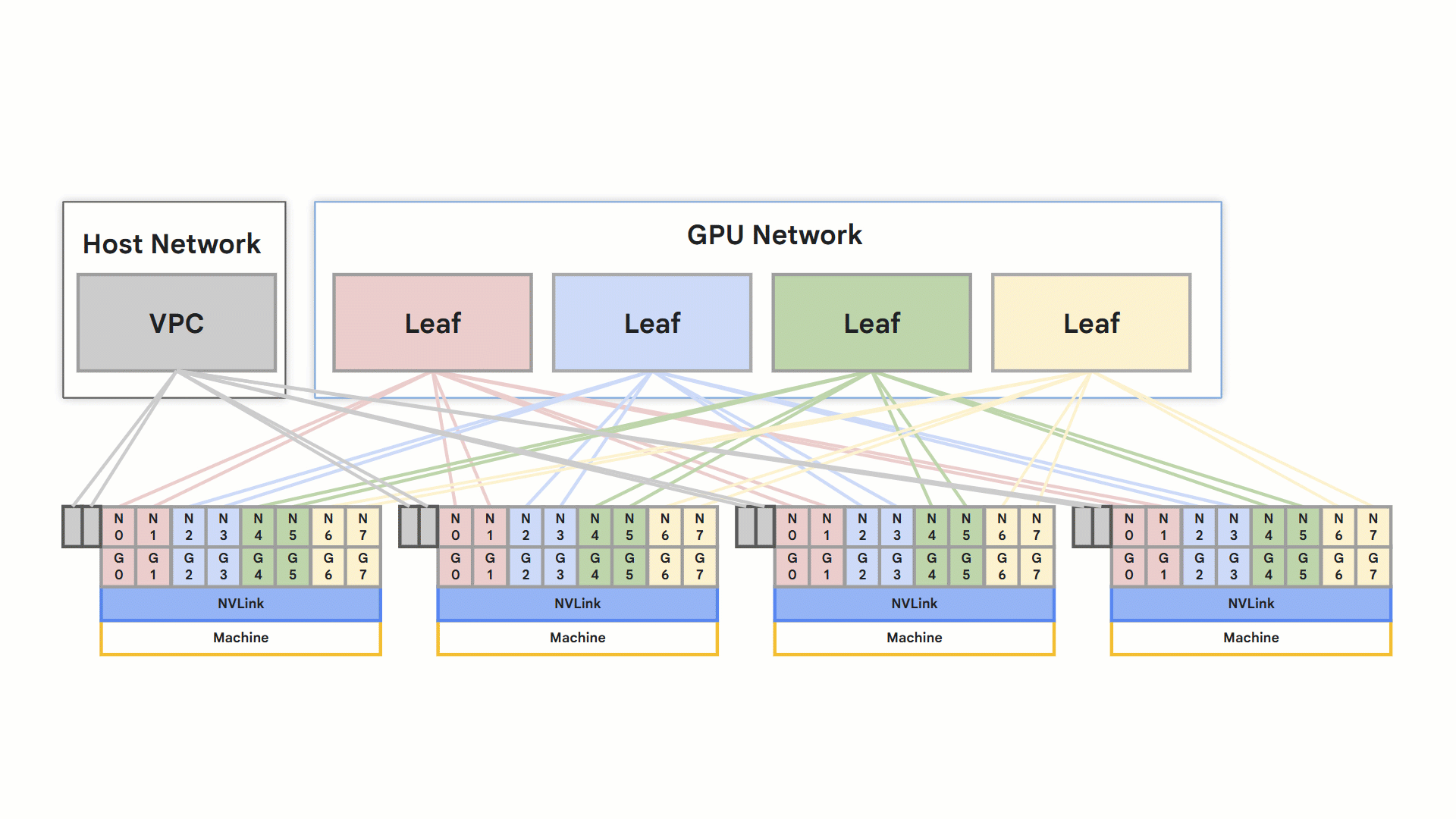
轨道式设计
总而言之,这些特性可以加快训练和推理速度,从而直接提升应用性能。这是通过一个为此目的而优化的专用 VPC 网络实现的。这种高性能连接是要求苛刻的应用的一个关键差异化优势。
### **开始使用**
要启用这些功能,请遵循以下步骤:
1. [创建预留](https://cloud.google.com/ai-hypercomputer/docs/request-capacity) :获取您的预留 ID;您可能需要与支持团队协作以申请容量。
2. [选择部署策略](https://cloud.google.com/ai-hypercomputer/docs/choose-strategy) **:** 指定部署区域、可用区、网络配置文件、预留 ID 和部署方法。
3. 创建您的部署。
您可以在以下文档中查看配置步骤和更多信息:
- 文档:[Hypercompute 集群](https://cloud.google.com/ai-hypercomputer/docs/create/create-overview)
- 博客:[面向 AI 工作负载的跨云网络支持](https://cloud.google.com/blog/products/networking/cross-cloud-network-solutions-support-for-ai-workloads)
- GCT YouTube 频道:[云开发者 AI 指南](https://www.youtube.com/playlist?list=PLIivdWyY5sqJio2yeg1dlfILOUO2FoFRx)
想要提问、了解更多信息或分享您的想法?欢迎通过 [Linkedin](https://www.linkedin.com/in/ammett/) 与我联系。
发布于
- [网络](https://cloud.google.com/blog/products/networking)
- [开发者与实践者](https://cloud.google.com/blog/topics/developers-practitioners)
<!-- AI_TASK_END: AI全文翻译 -->